Introduction
Network operators and system administrators confront frequent challenges that require them to integrate and exchange data between disparate systems to automate repetitive, time-consuming, complex, and error-prone tasks.
Consider a scenario where a network engineer is assigned to create a new VLAN for a department within their organization. This data transformation process entails receiving the initial request gathering supplementary details like IP address availability, existing switch configurations, and security policies from multiple sources such as IP address management (IPAM) systems, databases, and switches. The collected data must then be converted into the correct format for configuring network devices and generating the requisite Command Line Interface (CLI) commands. Following this mutation, the engineer applies the configurations to the devices, logs in to them through the CLI, and conducts testing and validation to ensure the new VLAN operates seamlessly while preserving existing network services.
An important step in any mutation is understanding the underlying issues involved. The traditional approach described above involves developing complex scripts or using middleware that requires a deep understanding of APIs, programming languages, and data schemas.
Moreover, they face issues such as–
- Data Inconsistency: Different systems use varied data formats, complicating integrations.
- Scalability: As the infrastructure grows, so does the complexity of data flows, making manual code changes unsustainable.
- Time Constraints: Performing transformations through traditional scripting and coding methods can be time-consuming, resulting in deployment delays and system integrations. In contrast, ATOM’s no-code approach aims to streamline the transformation process, saving valuable time and ensuring quicker and more efficient data integrations.
- Skill Gap: A significant challenge network operators face is the disparity in coding skills within their teams. Not all network operators have the coding expertise required for complex data transformations. This skill gap can lead to operational inefficiencies, dependency on a select few individuals with coding skills, and hindered data utilization. Bridging this gap is essential to enhance efficiency and automation in network operations. ATOM’s No-Code approach empowers a broader range of team members, regardless of their coding background, to perform complex data transformations and improve overall operational effectiveness.
The Process– What is Data Transformations?
Simply put, ‘Mutation’ is converting raw data into a meaningful and digestible format. It involves reshaping, mapping, and restructuring one data format to another. In the context of network administration, data mutation can play a pivotal role in the automation and integration of data, therefore enhancing efficiency.
The term ‘Transformations’ in the context of network operations is a synonym for an entirely manual, multi-step, labor-intensive process. But what if this could be done without writing a single line of code? ATOM data transformations ensure this process is automated, streamlined, and error-proofed. That’s what we aim to discuss here: a new age of data transformations using no-code solutions in ATOM. This approach revolutionizes how we think about and implement data mutation, making it integral to our journey toward comprehensive interoperability and automation.
The How– Synchronizing Solves the Problems
The beauty of data mutation lies in its ability to create a unified data layer that can be easily manipulated and moved between different systems. By transforming data, network operators can:
- Standardize Data: Ensure that data flowing between systems is consistent.
- Enhance Scalability: Mutation rules can be easily updated, making the system more flexible.
- Save Time: ATOM’s inline, on-the-fly data mutation eliminates the need for manual scripting and coding interventions.
- Bridge Skill Gaps: With no-code or low-code tools, even operators with limited coding experience can perform complex data manipulations.
The Why Not– Manual Implementation
While data mutation is indispensable, manual approaches come with their own set of challenges:
- Complexity: The diversity in data sources and formats can make transformations tricky.
- Resource-Intensive: Traditional methods might require significant computational power for manual data transformations or conversion.
- Usability: Not all mutation or transformation tools are user-friendly, and some require a steep learning curve.
The ATOM– Integrated platform for No-Code
ATOM revolutionizes the field by offering a no-code solution for data transformations. It incorporates features such as
Mutation Designer Tool:
The Mutation Designer Tool enables users to create and customize data mutation workflows through a user-friendly graphical interface. With this tool, you can visually design the way data is transformed, mapped, and structured, allowing you to define the mutation process step by step easily. This intuitive approach simplifies the often complex task of data mutation, making it accessible to a wide range of users, even those with limited technical or coding experience.
Mutation Engine:
The mutation Engine provides a versatile and adaptable solution for converting API payloads and JSON objects into different structures. It allows for the repetitive mutation of data, meaning that you can perform various parsing techniques and conversions multiple times to achieve the specific output you need. This flexibility ensures a seamless and customizable integration process, making it easier to meet various data mutation requirements.
Drag-and-Drop Interface:
Simplifies the mutation process, making it accessible for individuals without coding skills. Users can use ATOM’s workflow designer to drag, drop & create user and system tasks easily.
Achieving Unmatched Accuracy Through Intelligent Design:
Data mutation in ATOM significantly reduces the potential for human error, a common concern in manual network operations. This is achieved through its robust validation mechanisms and the utilization of pre-configured templates and existing mutation techniques.
Templates and Existing Transformation Techniques:
ATOM leverages pre-configured templates and established transformation techniques, which have been fine-tuned for accuracy and reliability. These templates serve as a foundation for data mutation, reducing the need for manual intervention and making the parsing methodology more robust and error-resistant. By building upon these templates, users can achieve highly accurate results consistently.
Elevating Efficiency Through Time Optimization:
What distinguishes data transformations in ATOM is its ability to condense what was once a time-consuming, manual task into a quick, automated process. With a user-friendly interface and pre-designed workflows, it gives users comfort by enabling them to concentrate on more value-added activities that go beyond mere data formatting, processing, and mutation.
Fostering Collaborative Innovations Through Reusability:
A cornerstone feature is the provision for reusable mutation modules. After the initial creation and successful testing of data transformations, the configuration can be saved and reused, thereby accelerating future use.
ATOM’s no-code approach aligns closely with the needs of modern network operations centers. Users can leverage this feature by significantly streamlining their operations.
Opening the doors to Dynamic Transformations with Advanced Features
ATOM consistently unveils fresh features, and the recent upgrade in the JSON Schema Transformation Canvas empowers users to create, edit, or import JSON schema templates effortlessly. This dynamic canvas streamlines the process, enabling you to specify input and output formats, mutation names, and detailed descriptions, ensuring smooth data transformation.
JSON data can also be converted to another JSON format using templates and predefined methods based on user requirements.
Schema Creation
- Users can easily create and manage JSON schema templates using the Schema Transformation canvas. They can also import and download these templates as needed.
Each template includes 3 components:
- Schema-spec(template): this includes the skeleton with respect to how the processing and conversion of incoming JSON needs to be done. Each schema template will contain Incoming Schema(input JSON format), Outgoing Schema(output JSON format), and Steps(method-wise execution/parsing logic).
- Mutation name: name of the template user-created
- Description: what the mutation template does.
Schema Execution
- Access the platform and go to the workflows/data mutation section.
- Open JST Designer: Use this tool to map your mutation requirements visually.
- Drag-and-Drop Operations: Use the canvas to perform mutation with the methods on the right pane.
- Test Transformations: After creating the data mutation template and configuring parsing libraries and functions, users can observe the real-time parsing output at each step of the process. This step-wise logging of parsed data is an invaluable feature, enabling users to test and debug the entire data mutation process thoroughly. It allows users to verify that the data is being transformed correctly at each stage, making identifying and addressing any issues or discrepancies easier. This real-time insight ensures that the mutation meets the user’s specific requirements and expectations.
- Deploy: Once a required mutation is achieved, deploy the mutation, which will be applied in real-time.
ATOM allows Mutation execution in 3 ways-
1. Execute from JSON Schema Transformations Canvas-
- A user can run a template(mutation) after creating the required template and saving it in the JSON Schema Mutation canvas.
- Input data to mutation must match the Incoming Schema format in the designed template.
- Running the template(mutation) will fetch the output in the same format as the user defined in the template.
2. Execute in Workflows as Catalog Item-
- Transformations are integrated within the Workflow Catalog in the workflow builder. We can make use of the mutation templates in any workflow.
- The Mutation Catalog item will take input data(from the user) and run the mutation script chosen from the catalog.
- The output from mutation is then embedded into the execution parameters as separate variables- to be used in further workflow processes.
3. Execute within any Workflow Tasks and Activities-
- Mutation scripts can be run within any workflow instance.
- Users can choose the Transformations Script type in Workflow Output Parameters for the corresponding activity/task.
- The incoming data(input) to the mutation will be coming from the output of the associated workflow task.
- After transformation, the output from mutation will be embedded into workflow execution variables for that workflow, which can be further used as required.

Fig: Transformations Template Canvas
In the illustration above, you can see a Transformations Template Canvas. This is where users can create new mutation templates or modify existing templates.
- On the left is the methods panel, which is used as an abstraction of complex functions and data manipulation that a user wants to perform on data.
- Each method converts one form of data to another.
- Users can define the format of data that needs to be transformed into another. The mutation template will perform all associated transformations and produce an output in the format that is predefined by the user.

Fig- Transformations Template Execution Details
For a better understanding of how data has been morphed at each step of the mutation cycle, the user can check each step of mutation in the Logs section:
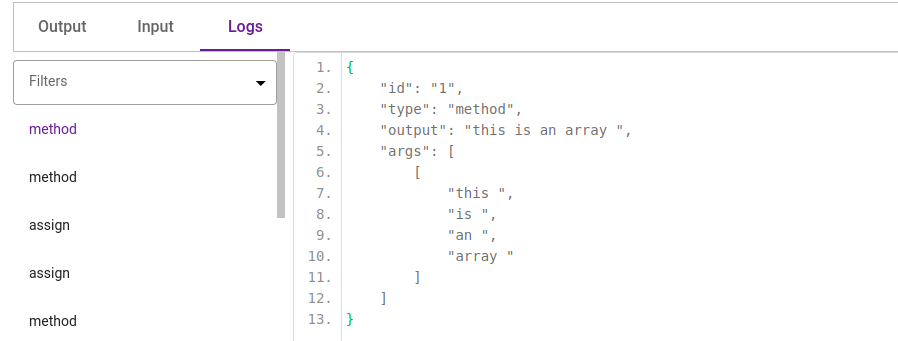
Fig- Transformations Template Step Wise Logs
Conclusion
ATOM offers a new approach to data transformations, eliminating the need for code and making the process scalable and user-friendly. This enables users to focus more on strategy and less on the nitty-gritty of data manipulation. ATOM’s data transformations aim at becoming a catalyst that empowers users to extract maximum value from their data without getting entangled in the intricacies of code.
Additional Contributors: Manisha Dhan